
Technology Tools
- Romax
Automatic Wade-Giles to Pinyin Romanization Converter for Chinese -
OCLC Connexion Korean Romanization Macro by Joel Hahn
Macro for use with OCLC Connexion client software; Look near the bottom of the page for "Korean2Latin" - OCLC
Connexion Chinese Romanization Macro by Thomas Ventimiglia
Princeton University East Asia Library and the Gest Collection -
K Romanizer by Hyoungbae Lee
Windows application for ALA-LC Korean Romanization
Princeton University East Asia Library and the Gest Collection - CJK IME Guide
(under construction) - CJK Compatibility Database
Library of Congress Cataloging Policy and Support Office
"Use the CJK Compatibility Database to quickly and conveniently replace non-MARC21 characters with MARC21 equivalents, or a missing character symbol."
- Finding CJK Unicode Codes
Tips for finding more information about Unicode encodings for CJK characters - What to do When Your Character is not in MARC 8
- The Changing Unihan Database: EACC and MARC 8
Step 1: Finding Your Character's Encoding
- Go to the Macchiatto Unicode 4.1.0 Chart noted below.
- Click the check-box “Show Code” (upper right)
- Paste your Chinese character into the search box, and click “Find”
NOTE: It's NOT necessary to change the drop-down labeled "Aegean_Numbers." Simply paste in your CJK character, and click "Find." - View the chart with characters and their Unicode values.
"Macchiato Unicode 4.1.0 Chart"
Search By Chinese Character for Unicode Value
Screen Shot
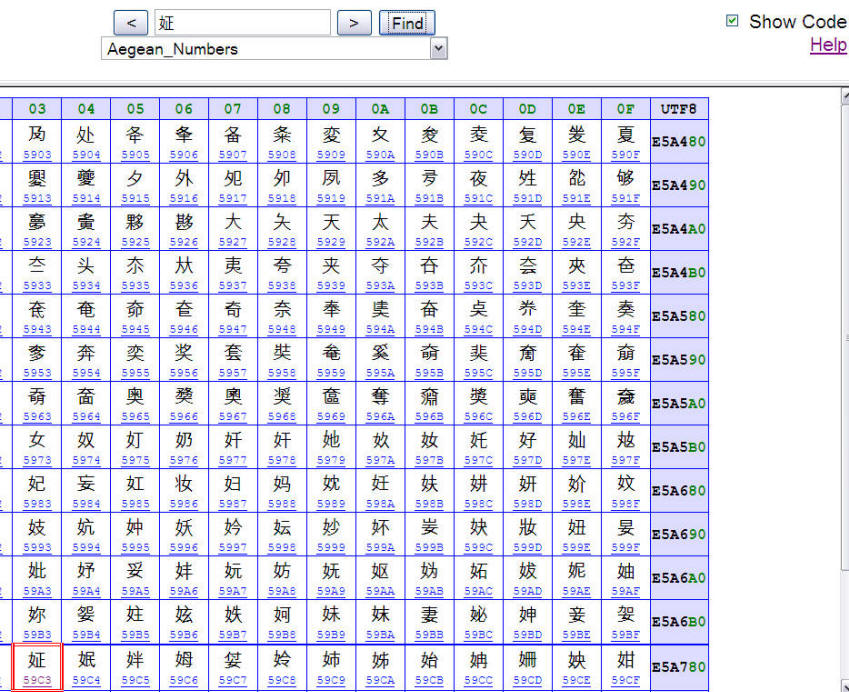
Step 2: Getting More information about your character
- Use the above method to find the Unicode value
- Go to the “Unihan Database Lookup” page to get more information about the character by searching its Unicode value
"Unihan Database"
Search By Code
Screen shot
Screen shot
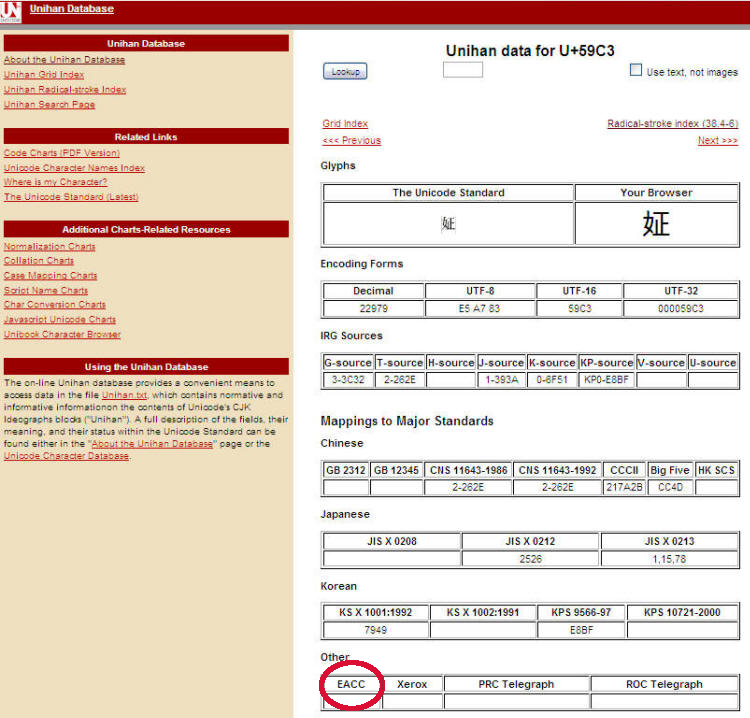
Information provided by Hisako Kotaka
- "EACC value"
EACC (East Asian Character Code) serves as the framework for the MARC 8 CJK character set used in the MARC 21 Standard. Unihan Database users will notice that the "EACC" field in the record for particular characters is sometimes empty. CJK Character records in the Unihan DB lacking an EACC value are not valid in the OCLC environment (although they are valid UTF-8 (Unicode) characters). - "Variants"
Some Unihan Database records for CJK characters include a link to a "Variant" character, which is another Unihan database record for a related character. Users should check variants to see whether or not the variant has an EACC value, and is therefore usable in the OCLC environment. - Moving Target
Although OCLC Used Unicode 4.0 for its OCLC Connexion ver. 2.10 MARC Verification program, Unihan is a dynamic file and its modification continues. As MARC 21/MARC 8 standards change, issues regarding CJK characters in cataloging and other metadata will also change.
When doing CJK cataloging in OCLC, only the sub-set of Unicode encoded characters known as "MARC 8" may be used. Occasionally, a non-MARC 8 character is used in an item being cataloged. Even though the character may be part of the Unicode character set, since it is not included in MARC 8, it is not possible to use the character in an OCLC record. Following are some suggestions for what to do in that case, provided by Hisako Kotaka at OCLC.
Enter a note field to clarify the missing character(s). Using "姃" (a character not included in MARC 8) as example, compose a 500 field as a clue to users, such as:
500 Missing Chinese character in the 700 field consists of 女 in
radical and 正, with Unicode code point 59C3.
Unicode code values can be searchable with "Character Map" in Microsoft Windows.
PLEASE
FOLLOW:
MS Program Accessories=> System Tools=> Character Map=> Click on “Advanced view” at this point and set Font=Arial Unicode MS ; Character set=Unicode ; Group by=Ideographs by Radicals.
All of the Unicode ideograph characters are displayed for you to
choose from, and you
will see the code point value of the selected character at the bottom of
the table. MS Program Accessories=> System Tools=> Character Map=> Click on “Advanced view” at this point and set Font=Arial Unicode MS ; Character set=Unicode ; Group by=Ideographs by Radicals.
If the user’s ILS has been configured with the UTF-8 characters handling, the missing character in the OCLC MARC master record should be properly displayable as 姃 once your local edit and export is done with UTF-8.
Section Top
Page Top

Please send questions or comments to the CLT Chair (2008-2014): Rob Britt (rrbritt@uw.edu).
Linking to the CEAL Homepage (PURL) Last Updated March 20, 2017 02:05:29 PM